csvデータからベクトル検索(qdrant)&全文検索(Meilisearch)用データに変換してブラウザから検索させるまで
csvデータからベクトル検索(qdrant)&全文検索(Meilisearch)用データに変換してブラウザから検索させるまで
関連する前回の記事↓

お世話になっております。
プログラマーのskkと申します。
前回ベクトル検索に必要な検索対象のデータセットを収集する
手法の紹介記事を書きましたが、
今回は収集したデータセットを
ベクトル検索用のデータとして変換、
更に全文検索用のデータにも変換、
合わせて2つの検索手法による検索用データを生成して、
それらに対する検索を行うシステムを
使用モジュール、手法あたりから紹介していきたいと思います。
システム全体の流れ
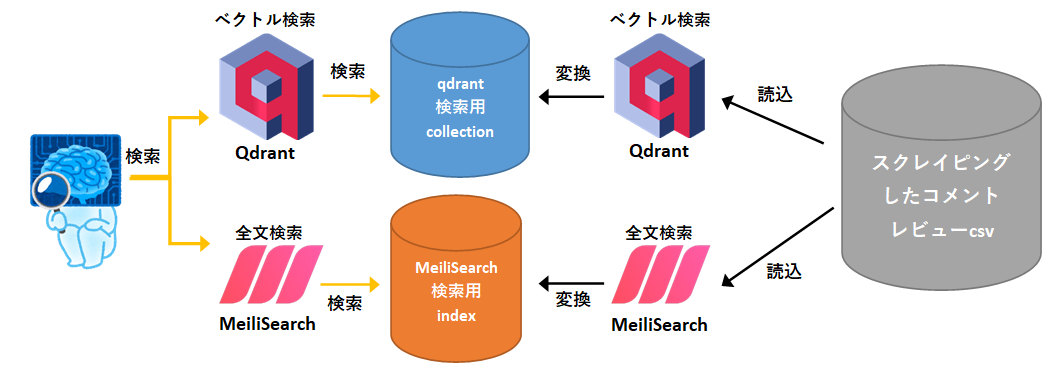
簡単な図ですが
今回のシステムは図のような流れになっております。
前回の方法等で集めたデータcsvを
2つの検索手法用のデータに変換、
ユーザー側からは
入力した検索キーワードをもって
2つのデータに対して検索を行い、
その結果を閲覧することができるものとなっております。
ベクトル検索「qdrant」
ベクトル検索とは、簡単にご説明しますと、
単語それぞれの意味を踏まえて行列データであるベクトル化を行い、
意味の近いものにはベクトルの方向を近づけることで
あいまいな検索を行うことができるようになっております。
例えば「野球」「サッカー」「パフェ」「ケーキ」というデータが登録されているとして、
これらをベクトル化した際に
検索側が「スポーツ」と入力してベクトル検索すれば「野球」「サッカー」が見つかり、
「甘い」と入力してベクトル検索すれば「パフェ」「ケーキ」が見つかるような仕組みとなっております。
企業ページにおけるチャットサポートであったり、
ChatGPTにおける会話形式での検索だったり、
Googleによる検索を行った際に検索キーワードと一致はしていないものの、
雰囲気の近いページが検索結果に表示されたりするのも
すべてベクトル検索により実現されています。
今回用意したデータセットはコメントレビューなので一行一行が文章形式で入っている
文をベクトル化する場合、文を言語上の最小単位である形態素(名詞、形容詞、動詞など)に分割し、
それぞれベクトル化して最終的にベクトル達の平均を取って一つのベクトルを作り、
それをもって文のベクトルとしています。
検索時に文を入れた時に近い文データを探してくれるようになっています。
日本語のデータの場合、英語と違い名称や接続詞の間で半角スペースが空いてないので
文のベクトル化の為に形態素分割(tokenizer)は必須となります。
また、ベクトル化に欠かせないのは辞書モデルデータです。
形態素をモデルと照らし合わせてベクトル化
検索時も同じモデルと照らし合わせてベクトル化して検索させるという流れになっています。
モジュール「SentenceTranceFormar」を使うと上記の
形態素解析、モデルデータと照らし合わせてのベクトル化までを
一括で行ってくれます。
「qdrant」を使うことで
元の文字列データと
変換後のベクトルデータをセットで保存することができます。
このセットに対してベクトルデータで検索することによって
元の文字列データを取り出す事ができます。
全文検索「Meilisearch」
今回ベクトル検索と合わせてもう一つの検索手法として
全文検索を導入しています。
これはデータすべての文字列を一つの全文にまとめて
一文字単位、もしくは形態素で分けて、それぞれの要素に行と列番の索引を付けて
検索時にこの索引に対して検索させることで
膨大な文字列に対して高速な検索を実現する仕組みとなっております。
「Meilisearch」を使い、
索引の作成と元の文字列データを合わせてデータセットとして記録させています。
日本語対応はまだ途上ですが、ある程度は問題なく検索できました。
検索フォーム、フロントページの作成 「Streamlit」
検索用データセットを作成したところで
ユーザー側から検索を行う為に
検索ページを作成しますが、
「Streamlit」を採用しました。
Pythonで表示用ページを作るためのフレームワークで
ブラウザアクセスできるようにサーバ公開まで容易に行ってくれる代物です。
挙動を説明するためのサンプルページ作成と展開ならStreamlitで事足りそうな感じです。
検索の組み合わせ
今回この2つの検索手法モジュールを
それぞれ
Streamlitと同じサーバ内に
dockerコンテナで立てており、
Streamlitアプリケーションからlocalhostでアクセスできるようにしました。
検索表示時には
Pandasモジュールでdataframeを扱うことで
結果の表示体裁を整えたりします。
今回2つの検索を行いましたが、
Pandasの機能も使って
検索結果を結合させ一つの表にしました。
ベクトル検索側は近似値を新たな列として持っているのですが、
全文検索側にも同じ列を作り2つの検索結果を同一の列に合わせたところで結合します。
(全文検索結果は検索キーワードが頻出している文字列から順に表示しているので一番最初の行を「0.999」最後の行を「0.700」と
近似値を設定して、間の行は均一に近似値を下げて割り当てる形にします。)
2つの検索結果を結合した後は
Pandasの機能で指定列でのソートや、重複行の削除を行うことで
ベクトル検索+全文検索を組み合わせた
1つの検索結果を作成することが出来ます。
このような組み合わせた検索手法で
Googleの検索結果のような状態を再現することも出来ます。
おわりに
今回はフローと技術紹介で新たな検索手法に関して紹介する記事でした。
もちろん今回紹介したモジュール以外にも多数のデータセット生成モジュールは存在します。
更に今後新たな検索技術が増えてくることも予想されます。
どんどん学んで行きたいところです。
サービスに活かすという点でも
ベクトル検索を用いたサービスで
現在ChatGPTが大きな発展を見せていますが、
この辺りのAI基軸としたサービス展開はまだまだ増加、及び拡大傾向にあると考えます。
入り口としてベクトル化の技術は今後も活かせそうな感じなので
個人的には追いかけられるように頑張りたいところです。
それでは。
Tweet