機械学習のモデル作成について考える
ゼッケン自動検出システム α版公開中
スペース・アイでは機械学習を使い、マラソン写真からゼッケン番号を自動で検出するシステムを開発しました。
開発のきっかけは、弊社サービスの写真販売プラットフォーム「フォトラボ」のユーザー様からの機能リクエストをいただき、まずはその運用ケースに沿った学習を行いました。
そのため
写真販売サイトで使う以上『写真を買いたい人』が検出されなければなりません。
ぼやけているゼッケンのランナーはきっとその人ではありません。
との制約を設けていたのですが、社内で上がった意見に
『デモ用なんだから、お客様から見たらどんなゼッケンを検出できるか知れた方がいいじゃない?』
ごもっとも!
そんな理由でモデルを作り直しました。
新モデルの精度
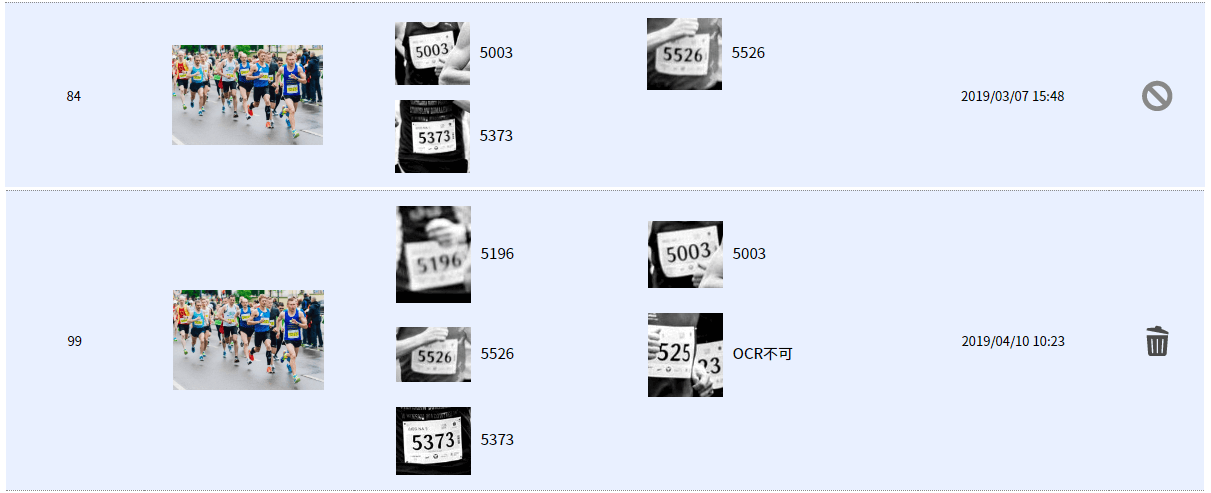
このように。
上段が前回のモデルで、下段が今回作り直したものです。

使用した元の写真と見比べますと、
前回のモデルはゼッケンがはっきり写っている5526,5003,5373の三名を検出していました。
新型モデルはぼやけている5196番、ゼッケンが隠れている○525番も検出しています。
検出できていないのはゼッケンが完全にぼやけている『5526番の右の人』
ゼッケンが半分以上隠れている『○○73番(?)』と『○525番の右の人』の三名。
またフリー素材ではないので掲載できませんが、
・若干たなびいているもののゼッケンとして認識できるもの
・写真の端で切れてしまったゼッケン
などもふくめ、80~90%の検出率を誇るようになりました。
※OCRでテキスト検出できるかは別問題
早速新型モデルをゼッケン検出システムZetectに導入。
裏方のお話
ここからは技術的なお話。
最初のモデルを作成した段階で用意した画像は約450枚×グレースケール化の計900枚。
また学習回数も7000回を超えたところで十分な結果が得られたので打ち止めにしました。
どうやって精度をあげようか
今回は検出範囲を広げることを考えたので、使用する画像は変わらず。
初回では腕などの障害物や、ゼッケンの大きさ、ぼやけ等でアノテーションしていなかった部分を対象に含め、
アノテーション量は実質1.5~1.8倍。
また学習回数を7000回としていましたが、新デモルでは学習結果の観察も視野に入れ
一旦、過学習になるまで学習しました。
その回数は2万回。この段階でゼッケンを検出できなく(正否判定が不可能に)なったので、
そこからモデルの作成基準を計算し、最終的に17,000回の学習データで作ったのが新しいモデルになります。
その制度はご覧の通りです。
同じ画像でも精度は上がる
今回のテストでわかるのは、使う画像が同じであってもアノテーション範囲、試行回数を変えることで精度は上がるということでしょうか。
勿論過学習やアノテーションをミスすれば精度は下がります。
どういったものを対象(今回ではゼッケン)と定め、仕事の片手間に機械学習を走査させる術を見つけることで
ディープラーニングはもっと簡単に、もっと精度を上げて行けると思われます。
また将来的な目標として、ユニフォームなどの衣服に番号が書かれている場合も取得できるようにしていきます。
(現行でもユニフォームを検出できる場合はありますが幾分不得手)
